Parallelizing a crossword composer in the browser
November 10, 2023Introduction
Back in 2021, I was reading about WebAssembly and decided to try it out for myself. I somehow ended up stumbling upon Paul Butler's crossword composer solution, which consists of a solver written in Rust, that compiles to Wasm and is called by a UI written in JavaScript. I got very intrigued by it. It looked like a great starting point to play a little bit with WebAssembly. However, the solution was already completed, what could I add to it?
Well, it turns out the crossword composing problem is NP-Complete and it takes a while to solve even with relatively simple grids. You can test that in Butler's deployed solution. I figured I could optimize it by applying concurrent computing inside the browser, using another tool I was wanting to play around with - Web Workers. That sounded like an interesting project: applying concurrent computing inside the browser, using Wasm, to optimize the solution of an NP-Complete problem.
How it works
Note: The functionality described below was entirely engineered by Paul, this is just my interpretation of it.
Solution flow
The grid is encoded in such a way that every cell has an identifier that maps to a letter. Words are therefore mapped as an array of these identifiers, in such a way that words with intersections between themselves will share same identifiers for their intersecting positions. The solver receives as an input a list of these letter identifier arrays, and outputs a dictionary matching identifiers to letters to fill the grid.
The diagram below tries to illustrate the entire flow.
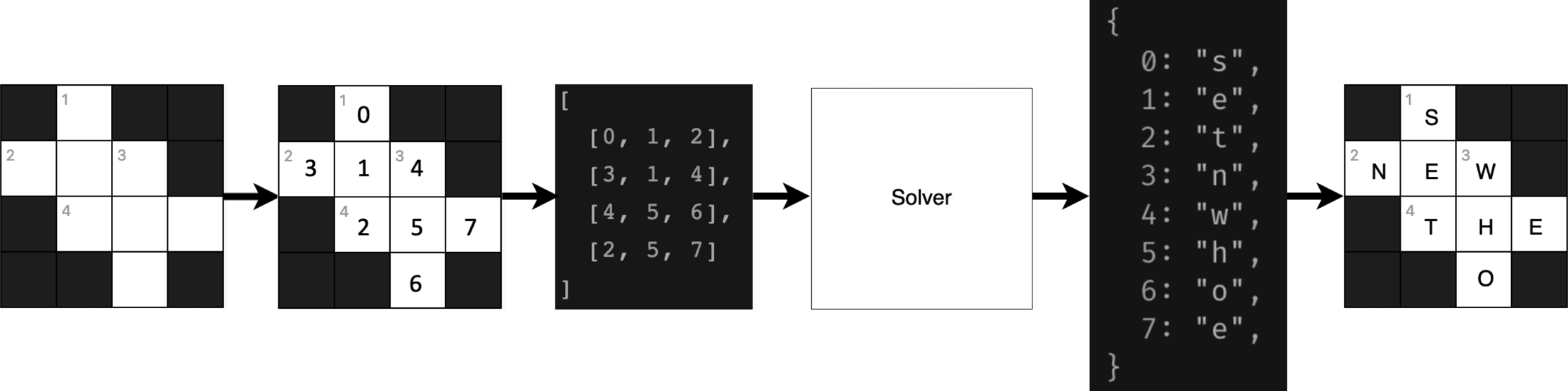 Crossword generation flow.
Crossword generation flow.
The solver
The solver utilizes a backtracking approach to find words that satisty all restrictions. It maps through the list of words, choosing words from a given dictionary that satisty the restrictions of length and intersections. If no fitting word is found, it backtracks to the previous word in the list, and changes it to another word from the dictionary. The process repeats until either all combination possibilities are explored without success or the first solution is found.
There are a few optimizations to this solver. You can find in Paul's repository a more in-depth explanation.
Parallelizing
The approach I took was simple, and probably still far from optimal, but it was a lot of fun to implement and yielded surprisingly good results. You can think of the whole backtracking solver algorithm as a depth-first search, and what I did was simply parallelize that search. If we have X number of words to start searching, and Y available workers, we will split the starting words by the number of available workers and feed each worker with a balanced amount of starting words.
For example, if we have 1000 possible starting words, and 8 available workers, each worker will receive 125 words to start searching. That means we will be searching concurrently for at least 8 different paths, reducing the chances of losing much time on dead ends. Obviously, every worker will have the full dictionary available to search for the rest of the words, just the possible words for the starting grid positions are narrowed down.
To implement this solution, I first tried to do everything in the solver, but at the time controlling Web Workers from Rust/Wasm was very obscure. So I made use of the web UI in JS/Svelte to create and control the Web Workers, and the Rust/Wasm code would simply get called from the workers with a given starting path and start the solution from there. The first worker to find a solution would signal back to the main thread to finish and terminate other workers. If all workers finish without a solution, it means we have no possible solution for given grid layout and dictionary.
You can find the implementation here (and a bunch of failed attempts in other branches).
Results
As we are parallelizing basically all of the work being done, we can expect to have fairly high speedups, close to linear. However, spawning Web Workers generally has a high overhead (see this). It turns out the results of the experiment were very undeterministic, as you can see below.
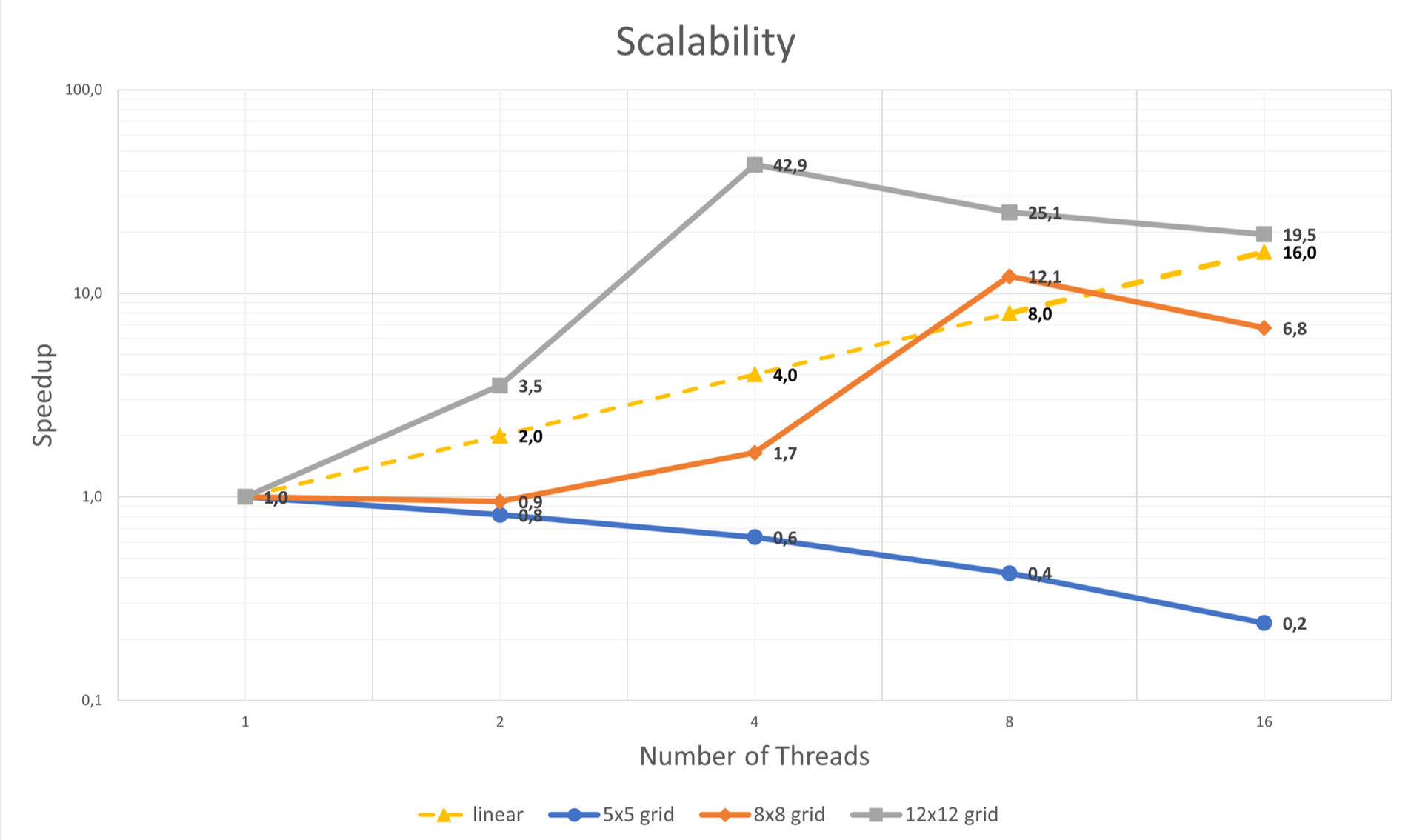 Speedup results by number of threads used, for different grid layouts. Experiments ran with i9
processor, 8 cores, and in Firefox.
Speedup results by number of threads used, for different grid layouts. Experiments ran with i9
processor, 8 cores, and in Firefox.
Even super-linear speedups were achieved, which for me at the time was very surprising. It is very intuitive if you think about it, though: going back to the of the nature of the problem, we can understand that the "best" path, or at least one of the better ones, can be in any path of the search. And the more searchers we have, searching through different branches of this tree, better are the odds of us finding those more quickly.
Analyzing the 8x8 grid results, for example, we can observe that from one to two threads there was no speedup increase, which means probably the second thread couldn't find any quicker solution with the paths it was given, compared to the ones the first one already had. If we look at four threads, there is already at least one quicker path found, giving us a 1.7 speedup, and at 8 threads, we achieve the super-linear speedup of 12.1. This could mean that one of the quickest paths is already given to one of the 8 threads, because if we look at 16 threads, there is a decrease in speedup, so we are probably only adding the overhead of Web Workers there.
Conclusions
I believe this study was still too preliminary to reach any deeper conclusions, but there was definetely some valuable learning here. Apart from learning a ton about WebAssembly, Web Workers and the Crossword Generation Problem, this experiment ended up showing me that parallelizing depth-first search based algorithms can lead to super-linear speedups, which is already very well known in the academia, but still, a very useful concept to have in mind.
For future work, there are a few ideas, mainly:
- Reiterating on the idea of writing the Web Worker controller from plain Rust/WebAssembly.
- Thinking of other strategies for parallelization or optimizations for this approach.
- Researching on utilizing shared data between different Web Workers (in my solution, each worker has to receive the full dictionary).
- Adding a toggle button to the UI to switch between parallel and sequential version, or even having a "race mode".
- Adding ability to, after having a solution, choose between words that satisfy the restrictions for a given grid position.
For Portuguese-speaking readers, you can check out a published version of an article I wrote on this project here.